Observable
Older versions: 2.x
Introduction #
The Observable is a data type for modeling and processing
asynchronous and reactive streaming of events with non-blocking
back-pressure.
The Observable is strongly inspired by
ReactiveX, but with an idiomatic Scala API and
influenced by the Scala ecosystem of projects such as
Cats and
Scalaz. It’s also compatible with the
Reactive Streams specification,
hence it has good interoperability.
// We need a Scheduler in scope in order to make
// the Observable produce elements when subscribed
import monix.execution.Scheduler.Implicits.global
import monix.reactive._
import concurrent.duration._
// We first build an observable that emits a tick per second,
// the series of elements being an auto-incremented long
val source = Observable.interval(1.second)
// Filtering out odd numbers, making it emit every 2 seconds
.filter(_ % 2 == 0)
// We then make it emit the same element twice
.flatMap(x => Observable(x, x))
// This stream would be infinite, so we limit it to 10 items
.take(10)
// Observables are lazy, nothing happens until you subscribe...
val cancelable = source
// On consuming it, we want to dump the contents to stdout
// for debugging purposes
.dump("O")
// Finally, start consuming it
.subscribe()
At its simplest, an Observable is a replacement for your regular
Iterable
or Scala
Stream,
but with the ability to process asynchronous events without blocking.
In fact, you can convert any Iterable into an Observable.
But this Observable implementation scales to complex problems, touching on
functional reactive programming (FRP),
and it can also model complex interactions between producers and consumers,
being a potent alternative for
the actor model.
Design Summary #
A visual representation of where it sits in the design space:
| Single | Multiple | |
|---|---|---|
| Synchronous | A | Iterable[A] |
| Asynchronous | Future[A] / Task[A] | Observable[A] |
The Monix Observable:
- models lazy & asynchronous streaming of events
- highly composable and lawful
- basically the Observer pattern on steroids
- you can also think of it as being like a Scala Future or like a Task, except with the ability to stream multiple items instead of just one, or you can think of it as an asynchronous and non-blocking Iterable with benefits
- models producer-consumer relationships, where you can have a single producer pushing data into one or multiple consumers
- works best for unidirectional communications
- allows fine-grained control over the execution model
- doesn’t trigger the execution, or any effects until a client
subscribes - allows cancellation of active streams
- never blocks any threads in its implementation
- does not expose any API calls that can block threads
- compatible with Scala.js like the rest of Monix
See comparisons with similar tools, like Akka or FS2.
Learning resources #
The following documentation barely scratches the surface of Observable and is rather incomplete.
If you find it lacking, make sure to check either the Observable API or
look at the comments in the code directly. We put a lot of focus on scaladocs.
Another great resource is the ReactiveX documentation, which opens doors to plenty of books, blog posts and Stack Overflow answers. There are significant differences in the model, but the majority of functions behave the same, so it is a fantastic source of examples and additional explanations.
And last but not the least, we are always happy to help on gitter channel. Any feedback regarding the documentation itself (like confusing wording) is really appreciated too.
Observable Contract #
An Observable can be thought of as the next layer of abstraction with regard to Observer and Subscriber.
An Observable can be described in the following way:
trait Observable[+A] {
def subscribe(o: Observer[A]): Cancelable
}
where an Observer is:
trait Observer[-T] {
def onNext(elem: T): Future[Ack]
def onError(ex: Throwable): Unit
def onComplete(): Unit
}
An Observer subscribes to an Observable, so the Observable internals need to respect the Observer contract when it passes element(s) to it. You can consider it being a higher level interface which abstracts away the details of the contract and handles it for the user.
How it works internally #
If you are inexperienced with non-blocking reactive streams, it probably sounds confusing. The understanding of the underlying model
is not necessary to be a successful user of the Observable, but if you would like to know anyway (also perhaps to contribute your own low level operators),
the following paragraph tries to explain the essence of how it works. Note that the implementations of many operators are sometimes obfuscated with optimizations, which make them look much more
complicated than they really are.
An Observable will pass through the generated items to the Observer, by calling onNext.
Imagine the following situation:
Observable.fromIterable(1 to 3)
.map(i => i + 2)
.map(i => i * 3)
.sum
.firstL // returns Task[Long]
fromIterable is a builder which creates an Observable. Hence, it implements subscribe. This method passes
each element to its subscribers by calling its onNext method. Once the sequence is empty it calls onComplete to signal that there aren’t any
elements left to process and the entire Observable can end.
Note that the observer.onNext(elem) returns a Future[Ack]. To obey the contract and preserve back-pressure, the Observable will have to wait for its result before it can pass the next element.
Ack can be either Continue (ok to send the next element) or Stop (we should shut down).
This way, we can stop the downstream processing (by calling onComplete) and the upstream (returning Stop after onNext).
map is essentially an Observer => Observer function. It implements onNext, onError and onComplete.
The happy path goes like:
(1) fromIterable calls map1.onNext(i)
(2) map1 does some transformation and calls map2.onNext(i + 2)
(3) map2 does some transformation and calls sumL.onNext(i * 3)
(4) sum saves and acknowledges the incoming items and holds off on calling firstL.onNext until it receives an onComplete signal.
(5) firstL waits for the first onNext signal to complete a Task
Points (1) to (3) iterate until the entire sequence of elements (in this case, numbers) are consumed.
When sum acknowledges (returns from onNext method) to its caller map2, map2 in turn can acknowledge to its caller map1, which then
acknowledges to its caller fromIterable - only then can a new element be sent.
In case any onNext invocations return a Stop, this would also propagate upstream and there wouldn’t be any new elements generated.
If you try to jump into the source code of operators, you will see that they are obfuscated by concurrency, error handling and lots of optimizations, but the essence of the model works as described above. There is nothing more to it, no extra interpreters or materializers to add an extra layer of indirection - so if this section makes sense to you, you should have a decent idea of what’s going on “behind the scenes”.
Observable and Functional Programming #
The Observable internals are written in an imperative, Java-like style. It doesn’t look pretty and can be discouraging
if you’re trying to write your own operator. However, by using a relatively simple model (in terms of operations to do) the implementation
is very performant and this design choice is a big reason why it does so well in comparison to the competition.
Despite a mostly-imperative base, an Observable exposes a vast number of purely functional operators that compose really well, allowing you to build functionality on top of them in
similar way to how it’s done in other streaming libraries from the FP ecosystem.
If you’re mostly using available methods and want to write a purely functional application then you’re in luck because the
dirty internals don’t leak outside and the majority of the API and the process of constructing and executing Observables are all pure.
The main drawback in comparison to purely functional streams, such as fs2 or
Iterant, is the presence of impure functions in the API. If you have inexperienced
team members, they could be tempted to use them. Fortunately, all of them are marked with the @UnsafeBecauseImpure annotation and are explained in the ScalaDoc.
There should always be a referentially transparent replacement to solve your specific use case but if your team is not fully committed to FP, these functions can be very useful.
For instance, an efficient and convenient way to share an Observable is by using a hot Observable - but it’s not referentially transparent.
Nevertheless, you could do the same thing using the doOnNext or doOnNextF together with some purely functional concurrency structures from Cats-Effect such as Ref or MVar to share state in a more controlled manner.
Just like in Scala itself, the decision is up to the user to choose what’s better for them and their team.
Execution #
When you create an Observable nothing actually happens until subscribe is called.
Processing can be triggered directly by calling subscribe()(implicit s: Scheduler): Cancelable which starts
in the background and return a Cancelable which can be used to stop the streaming.
If you write programs in purely functional manner and would rather combine the results of Observables,
you can convert them to Tasks and compose them all the way through your program until the very end (Main method).
The resulting Task can also be cancelled and is the recommended way to execute an Observable.
Two main ways to convert an Observable into a Task are described below.
Consumer #
One of the ways to trigger an Observable is to use a Consumer - which can thought of as a function that converts an Observable into a Task.
You can either create your own Consumer or use one of the many prebuilt ones:
val list: Observable[Long] =
Observable.range(0, 1000)
.take(100)
.map(_ * 2)
val consumer: Consumer[Long, Long] =
Consumer.foldLeft(0L)(_ + _)
val task: Task[Long] =
list.consumeWith(consumer)
You can find more examples in the Consumer documentation.
FoldLeft Methods #
Any method suffixed with L in the API converts an Observable into a Task.
For example, you can use the firstL method to obtain the first element of the Observable:
// Task(0)
val task: Task[Int] = Observable.range(0, 1000).firstL
The following example achieves the same result as the previous section on Consumer:
val list: Observable[Long] =
Observable.range(0, 1000)
.take(100)
.map(_ * 2)
val task: Task[Long] =
list.foldLeftL(0L)(_ + _)
Building an Observable #
These methods are available via the Observable companion object. Below are several examples:
Observable.pure (now) #
Observable.pure (alias for now) simply lifts an already known value in the Observable context.
val obs = Observable.now { println("Effect"); "Hello!" }
//=> Effect
// obs: monix.reactive.Observable[String] = NowObservable@327a283b
Observable.delay (eval) #
Observable.delay (alias for eval) lifts non-strict value in the Observable. It is evaluated upon subscription.
val obs = Observable.delay { println("Effect"); "Hello!" }
// obs: monix.reactive.Observable[String] = EvalAlwaysObservable@48a8050
val task = obs.foreachL(println)
// task: monix.eval.Task[Unit] = Task.Async$1782722529
task.runToFuture
//=> Effect
//=> Hello!
// The evaluation (and thus all contained side effects)
// gets triggered on each runToFuture:
task.runToFuture
//=> Effect
//=> Hello!
Observable.evalOnce #
Observable.evalOnce takes a non-strict value and converts it into an Observable
that emits a single element and memoizes the value for subsequent invocations.
It also has guaranteed idempotency and thread-safety:
val obs = Observable.evalOnce { println("Effect"); "Hello!" }
// obs: monix.reactive.Observable[String] = EvalOnceObservable@3233e694
val task = obs.foreachL(println)
// task: monix.eval.Task[Unit] = Task.Async$1782722529
task.runToFuture
//=> Effect
//=> Hello!
// Result was memoized on the first run!
task.runToFuture.foreach(println)
//=> Hello!
Observable.fromIterable #
Observable.fromIterable converts any Iterable into an Observable:
val obs = Observable.fromIterable(List(1, 2, 3))
// obs: monix.reactive.Observable[Int] = IterableAsObservable@7b0e123d
obs.foreachL(println).runToFuture
//=> 1
//=> 2
//=> 3
Observable.suspend (defer) #
Observable.suspend (alias for defer) allows suspending side effects:
import monix.eval.Task
import monix.reactive.Observable
import scala.io.Source
def readFile(path: String): Observable[String] =
Observable.suspend {
// The side effect won't happen until subscription
val lines = Source.fromFile(path).getLines()
Observable.fromIterator(Task(lines))
}
Observable.raiseError #
Observable.raiseError constructs an Observable that calls onError on any subscriber emitting specified Exception:
val observable = Observable.raiseError[Int](new Exception("my exception"))
// observable: monix.reactive.Observable[Int]
{
observable
.onErrorHandle {ex => println(s"Got exception: ${ex.getMessage}"); 1}
.foreachL(println)
}
//=> Got exception: my exception
//=> 1
Sending elements to an Observable #
There are several options to feed an Observable with elements from another part of an application.
Observable.create #
Observable.create is a builder for creating an Observable from sources which can’t be back-pressured.
It takes a f: Subscriber.Sync[A] => Cancelable. Subscriber.Sync is an Observer with a built-in Scheduler which
doesn’t have to worry about the back-pressure contract, which makes it safe to use even for inexperienced Observable users.
An Observable which is returned by the method will receive all elements which were sent to the Subscriber.
Since they could be sent concurrently, it buffers the elements when busy, according to the specified OverflowStrategy.
Cancelable can contain special logic in case the subscription is canceled:
import monix.eval.Task
import monix.execution.Ack
import monix.reactive.Observable
import monix.reactive.OverflowStrategy
import monix.reactive.observers.Subscriber
import scala.concurrent.duration._
def producerLoop(sub: Subscriber[Int], n: Int = 0): Task[Unit] = {
Task.deferFuture(sub.onNext(n))
.delayExecution(100.millis)
.flatMap {
case Ack.Continue => producerLoop(sub, n + 1)
case Ack.Stop => Task.unit
}
}
val source: Observable[Int] =
Observable.create(OverflowStrategy.Unbounded) { sub =>
producerLoop(sub)
.guarantee(Task(println("Producer has been completed")))
.runToFuture(sub.scheduler)
}
source.takeUntil(Observable.unit.delayExecution(250.millis)).dump("O")
// Output after execution:
// 0: O --> 0
// 1: O --> 1
// Producer has been completed
// 2: O completed
Subscriber has an underlying Scheduler which can be used to run producerLoop inside of Observable.create.
Note that the function is still pure - no side effect can be observed before the Observable is executed.
Task#runToFuture returns a CancelableFuture. You can use it to return a Cancelable from a function, or you can just use
Cancelable.empty.
The former choice will be able to cancel a producerLoop during delayExecution(100.millis) if the source is canceled.
The latter will short-circuit when a Stop event is returned.
Observable.repeatEvalF + concurrent data structure #
The monix-catnap module provides a ConcurrentQueue which can be used
with the Observable.repeatEvalF builder to create an Observable from it.
import monix.catnap.ConcurrentQueue
import monix.eval.Task
import monix.reactive.Observable
def feedItem[A](queue: ConcurrentQueue[Task, A], item: A): Task[Unit] = {
queue.offer(item)
}
def processStream[A](observable: Observable[A]): Task[Unit] = {
observable
.mapParallelUnordered(3)(i => Task(println(i)))
.completedL
}
{
ConcurrentQueue.unbounded[Task, Int]().flatMap { queue =>
Task
.parZip2(
feedItem(queue, 2),
processStream(Observable.repeatEvalF(queue.poll))
)
}
}
The ConcurrentQueue has a bounded variant which will back-pressure the producer if it is too fast.
If you’re curious as to why we have to flatMap in this case, see the excellent presentation by Fabio Labella.
Note that you can also create an Observable from the other tools for concurrency, such as MVar or Deferred.
ConcurrentSubject #
You can use a ConcurrentSubject to get similar functionality:
import monix.eval.Task
import monix.execution.Ack
import monix.reactive.subjects.ConcurrentSubject
import monix.reactive.{MulticastStrategy, Observable, Observer}
val subject: ConcurrentSubject[Int, Int] =
ConcurrentSubject[Int](MulticastStrategy.replay)
def feedItem[A](observer: Observer[A], item: A): Task[Ack] = {
Task.deferFuture(observer.onNext(item))
}
def processStream[A](observable: Observable[A]): Task[Unit] = {
observable
.mapParallelUnordered(3)(i => Task(println(i)))
.completedL
}
{
Task
.parZip2(
feedItem(subject, 2),
processStream(subject)
)
}
One important difference is that subject will be shared between subscribers (here it is implied in the processStream method).
It might not be noticeable with MulticastStrategy.replay which caches incoming elements.
If we use a different strategy such as MulticastStrategy.publish, processStream won’t receive any elements which were sent before subscription.
Back-pressure, buffering, throttling #
The Observable is back-pressured, i.e. if the producer (upstream) is faster than consumer (downstream), the producer will
wait for an Ack from the consumer before sending the next element. However, that’s not always desirable.
For instance, we might want to process messages in batches for better throughput, or have strict latency requirements
which we need to fulfil even at the cost of dropping some messages. Fortunately, Monix provides a ton of operators in this space.
OverflowStrategy #
Many operators which limit, or disable back-pressure will take an OverflowStrategy as a parameter. The following are the policies available:
Unboundeddoes not limit the size of the buffer, which means an upstream won’t ever be back-pressured. If there is a lot of traffic and the downstream is very slow, it can lead to high latencies and even out of memory errors if the buffer grows too large.Fail(bufferSize: Int)will send anonErrorsignal to downstream, ending theObservableif the buffer grows too large.Backpressure(bufferSize: Int)will back-pressure an upstream if the buffer grows too large.DropNew(bufferSize: Int)will drop incoming elements if the buffer grows too large. This version is more efficient thanDropOld.DropOld(bufferSize: Int)will drop the oldest elements if the buffer grows too large.ClearBuffer(bufferSize: Int)will clear the buffer if it grows beyond limit.
DropNew, DropOld and ClearBuffer allow to send a signal downstream if the buffer reaches its capacity.
Asynchronous processing #
We can think of a back-pressured stream as synchronous processing, where the upstream waits until a particular element has been fully processed.
val stream = {
Observable("A", "B", "C", "D")
.mapEval(i => Task { println(s"1: Processing $i"); i ++ i })
.mapEval(i => Task { println(s"2: Processing $i") }.delayExecution(100.millis))
}
// Output when executed
// 1: Processing A
// 2: Processing AA
// 1: Processing B
// 2: Processing BB
// 1: Processing C
// 2: Processing CC
// 1: Processing D
// 2: Processing DD
Asynchronous processing would then be a case in which the downstream acknowledges new events immediately and processes them independently.
The Observable provides the asyncBoundary method which creates a buffered asynchronous boundary.
The buffer is configured according to the OverflowStrategy.
val stream = {
Observable("A", "B", "C", "D")
.mapEval(i => Task { println(s"1: Processing $i"); i ++ i })
.asyncBoundary(OverflowStrategy.Unbounded)
.mapEval(i => Task { println(s"2: Processing $i") }.delayExecution(100.millis))
}
// Output when executed
// 1: Processing A
// 1: Processing B
// 1: Processing C
// 1: Processing D
// 2: Processing AA
// 2: Processing BB
// 2: Processing CC
// 2: Processing DD
In the example above, we introduced asyncBoundary before last mapEval which introduced an unbounded buffer before this operation.
From the perspective of the upstream, the downstream is always keeping up with all the elements so it can always take the next one from the source.
Anything after the asyncBoundary is back-pressured as usual - each 2: Processing XX will be emitted in 100 millisecond intervals.
You can use another OverflowStrategy, e.g. OverflowStrategy.BackPressure(2), which would return following output:
1: Processing A
1: Processing B
1: Processing C
2: Processing AA
2: Processing BB
1: Processing D
2: Processing CC
2: Processing DD
When AA is being processed in the second stage, the source can send two more (size of the buffer) elements,
after which, it is back-pressured until there is more space available.
Processing elements in batches #
Operations like asyncBoundary and ConcurrentSubject will introduce internal buffers which we can’t access.
We can also buffer elements to process elements in batches.
bufferSliding #
Observable#bufferSliding emits buffers every skip items, each containing count items.
If the stream completes, it will emit an incomplete buffer downstream.
In case of an error, it will be dropped.
The bundles can overlap, depending on parameters:
- In case of
skip == count, then all elements are emitted without any overlap - In case of
skip < count, then buffers overlap with the number of elements repeated beingcount - skip - In case of
skip > count, thenskip - countelements start getting dropped between windows
Let’s take a look at an example demonstrating the case of skip > count:
Observable.range(2, 7).bufferSliding(count = 2, skip = 3).dump("O")
// Output when executed
// 0: O --> WrappedArray(2, 3)
// 1: O --> WrappedArray(5, 6)
// 2: O completed

The element 4 has been skipped. If the situation was reversed, it would be duplicated instead:
Observable.range(2, 7).bufferSliding(count = 3, skip = 2).dump("O")
// Output when executed
// 0: O --> WrappedArray(2, 3, 4)
// 1: O --> WrappedArray(4, 5, 6)
// 2: O completed

For skip == count scenario, take a look at the bufferTumbling example.
bufferTumbling #
Observable#bufferTumbling will gather elements and emit them in non-overlapping bundles of a specified count.
It is essentially bufferSliding where count is equal to skip.
If the stream completes, it will emit an incomplete buffer downstream.
In case of an error, it will be dropped.
def bufferTumbling(count: Int): Observable[Seq[A]]
Observable.range(2, 7).bufferTumbling(count = 2).dump("O")
// Output when executed
// 0: O --> WrappedArray(2, 3)
// 1: O --> WrappedArray(4, 5)
// 2: O --> WrappedArray(6)
// 3: O completed

bufferTimed #
You can also buffer elements depending on a duration, using bufferTimed(timespan: FiniteDuration).
Observable.intervalAtFixedRate(100.millis).bufferTimed(timespan = 1.second).dump("O")
// Emits 10 elements each second when executed
// 0: O --> List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
// 1: O --> List(10, 11, 12, 13, 14, 15, 16, 17, 18, 19)
// 2: O --> List(20, 21, 22, 23, 24, 25, 26, 27, 28, 29)
// ...
bufferTimedAndCounted #
Using either bufferTimed or bufferCounted has its drawbacks.
In bufferTimed, the buffer sizes can be very inconsistent, so you might have to wait on more elements even if we could
already be processing them, increasing latency.
When using bufferCounted, there is a risk of waiting a very long time (or forever) until there are enough elements to send downstream.
If these are possible issues in an application, you could use bufferTimedAndCounted to do both at the same time.
This buffering method emits non-overlapping bundles, each of a fixed duration specified by the timespan argument,
or a maximum size specified by the maxCount argument (whichever is reached first).
val stream = {
(Observable(1, 2, 3) ++ Observable.never)
.bufferTimedAndCounted(timespan = 1.second, maxCount = 2)
.dump("O")
}
// Output when executed
// 0: O --> List(1, 2)
// 1: O --> List(3)
// 2: O --> List()
// 3: O --> List()
// ...
bufferIntrospective #
There are more sophisticated buffering options available and one of them is bufferIntrospective(maxSize: Int).
This operator buffers elements only if the downstream is busy, otherwise it sends them as they come.
Once the buffer is full, it will back-pressure upstream.
val stream = {
Observable.range(1, 6)
.doOnNext(l => Task(println(s"Started $l")))
.bufferIntrospective(maxSize = 2)
.doOnNext(l => Task(println(s"Emitted batch $l")))
.mapEval(l => Task(println(s"Processed batch $l")).delayExecution(500.millis))
}
// Output when executed
// Started 1
// Emitted batch List(1)
// Started 2
// Started 3
// Processed batch List(1)
// Emitted batch List(2, 3)
// Started 4
// Started 5
// Processed batch List(2, 3)
// Emitted batch List(4, 5)
// Processed batch List(4, 5)
The example is a quite involved one so let’s break it down:
- Element
1can be started immediately and since the downstream is free, it is passed until the end - There is a free space in the buffer, so elements
2and3can be started - Now, the buffer is filled-up, so the upstream is back-pressured
- Once the first batch has been processed,
bufferIntrospectivecan send a new one - There is a space in the buffer again so
4and5can start, and they will be emitted when the current batch has been processed
bufferWithSelector #
Next sophisticated buffering operator is bufferWithSelector(selector, maxSize).
It takes a selector Observable and emits a new buffer whenever it emits an element.
The second parameter, maxSize determines the maximum size of the buffer - if it is exceeded, the upstream will be back-pressured.
Any size below 1 will use an unbounded buffer.
Let’s take a look at an example similar to the one with bufferIntrospective but this time it will emit elements every 100 milliseconds.
val stream = {
Observable.range(1, 6)
.doOnNext(l => Task(println(s"Started $l")))
.bufferWithSelector(selector = Observable.intervalAtFixedRate(initialDelay = 100.millis, period = 100.millis), maxSize = 2)
.doOnNext(l => Task(println(s"Emitted batch $l")))
.mapEval(l => Task(println(s"Processed batch $l")).delayExecution(500.millis))
}
// Output when executed
// Started 1
// Started 2
// Started 3
// Emitted batch List(1, 2)
// Started 4
// Processed batch List(1, 2)
// Emitted batch List(3, 4)
// Started 5
// Processed batch List(3, 4)
// Emitted batch List(5)
// Processed batch List(5)
The output can be a bit confusing because it suggests that element 3 has been started before emitting the first batch.
In reality, it was back-pressured as expected but emitting a batch downstream and acknowledging upstream is a concurrent operation, so
it could happen before the “Emitted batch …” print-out.
Since bufferWithSelector takes an Observable, it can be used to customize buffering to a pretty great extent.
For instance, we could use MVar or Semaphore to
buffer messages until we receive a signal from a different part of the application.
def bufferUntilSignalled(mvar: MVar[Task, Unit]): Observable[Seq[Long]] = {
Observable.range(1, 10000)
.bufferWithSelector(Observable.repeatEvalF(mvar.take))
// do something with buffers
}
val program = for {
mvar <- MVar.empty[Task, Unit]
_ <- bufferUntilSignalled(mvar).completedL.startAndForget
_ <- mvar.put(()) // signal buffer to be sent
} yield ()
bufferTimedWithPressure #
Observable#bufferTimedWithPressure is similar to bufferTimedAndCounted but it applies back-pressure if the buffer is full,
instead of emitting it. Another difference is that it allows to pass a function to calculate the weight of an element.
sealed trait Elem
case object A extends Elem
case object B extends Elem
case object C extends Elem
val sizeOf: Elem => Int = {
case A => 1
case B => 2
case C => 3
}
val stream = {
Observable(A, B, C, C, A, B)
.bufferTimedWithPressure(period = 1.second, maxSize = 3, sizeOf = sizeOf)
.dump("O")
}
// Output when executed
// 0: O --> List(A, B)
// 1: O --> List(C)
// 2: O --> List(C)
// 3: O --> List(A, B)
// 4: O completed
Limiting the rate of emission of elements #
The following subsection covers some of the operators that can help with limiting the rate and/or filtering of incoming events. As usual, there is more information in the API and if you’re missing something familiar from ReactiveX then it is most likely an easy addition - so do not hesitate to open an issue.
throttle #
The purpose of throttle(period, n) is to control the rate of events emitted downstream.
The operator will buffer incoming events up to n and emit them each period as individual elements.
Once the internal buffer is filled, it will back-pressure the upstream.
// Emits 1 element per 1 second
Observable.fromIterable(0 to 10).throttle(1.second, 1)
An important difference from the other throttling operators is that throttle does not skip any elements.
throttleFirst #
Observable#throttleFirst(interval) emits only the first item from the source in specified intervals.
Other elements will be dropped. The most classic use case of this operator is to avoid multiple clicks on the same button
in user-facing features.
val stream = {
Observable.fromIterable(0 to 10)
.delayOnNext(200.millis)
.throttleFirst(1.second)
.dump("O")
}
// Emits in 1 second intervals:
// 0: O --> 0
// 1: O --> 5
// 2: O --> 10
// 3: O completed
throttleLast (sample) #
throttleLast (aliased to sample) is similar to throttleFirst but it always emits the most recent (last one) element in the window.
val stream = {
Observable.fromIterable(0 to 10)
.delayOnNext(200.millis)
.throttleLast(1.second)
.dump("O")
}
// Emits in 1 second intervals:
// 0: O --> 3
// 1: O --> 8
// 2: O --> 10
// 3: O completed
throttleWithTimeout (debounce) #
throttleWithTimeout (aliased to debounce) will drop any events that were emitted in a short succession.
An event will be passed to downstream only after a given timeout passes. Each event resets the timer, even if it is dropped.
The operator will wait until it is “calm” and then emit the latest event.
This behavior is different from throttleFirst and throttleLast where the time window was static.
This operator is well-suited for situations like a search query - it can be quite expensive for the downstream to process
each key entered by a user, so instead we could wait until the user stopped typing before we send the events.
val stream = {
(Observable("M", "O", "N", "I", "X") ++ Observable.never)
.delayOnNext(100.millis)
.scan("")(_ ++ _)
.debounce(200.millis)
.dump("O")
}
// Output:
// 0: O --> MONIX
Note that if the source emits elements too fast and ends, all elements will be skipped, as presented in the next example:
val stream = {
Observable.fromIterable(0 to 10)
.delayOnNext(200.millis)
.throttleWithTimeout(1.second)
.dump("O")
}
// Output after execution
// 0: O completed
Transforming Observables #
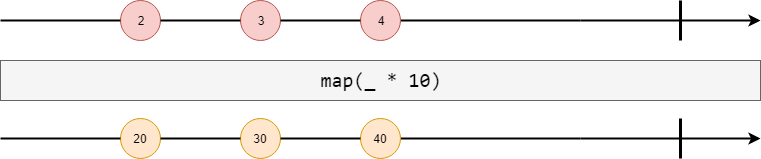
map #
Observable#map applies a function f to all elements in the source stream.
import monix.execution.Scheduler
import monix.execution.exceptions.DummyException
import monix.reactive.Observable
val stream = {
Observable.range(1, 5)
.map(el => s"new elem: $el")
}
stream.foreachL(println).runToFuture
// new elem: 1
// new elem: 2
// new elem: 3
// new elem: 4
Prefer to use functions that are total because any exception will terminate the stream (see Error Handling section) :
val failed = {
Observable.range(1, 5)
.map(_ => throw DummyException("avoid it!"))
}
failed.subscribe()
// monix.execution.exceptions.DummyException: avoid it!
// at MapObservable$.$anonfun$failedStream$1(MapObservable.scala:14)
// at MapObservable$.$anonfun$failedStream$1$adapted(MapObservable.scala:14)
// at monix.reactive.internal.operators.MapOperator$$anon$1.onNext(MapOperator.scala:41)
mapEval #
Observable#mapEval is similar to map but it takes a f: A => Task[B] which represents a function with an effectful result that can produce at most one value.
val stream = Observable.range(1, 5).mapEval(l => Task.evalAsync(println(s"$l: run asynchronously")))
stream.subscribe()
// 1: run asynchronously
// 2: run asynchronously
// 3: run asynchronously
// 4: run asynchronously
There is also a mapEvalF variant for other types which can be converted to a Task, i.e. Future, cats.effect.IO, ZIO etc.
import scala.concurrent.Future
val stream = Observable.range(1, 5).mapEvalF(l => Future(println(s"$l: run asynchronously")))
stream.subscribe()
// 1: run asynchronously
// 2: run asynchronously
// 3: run asynchronously
// 4: run asynchronously
mapParallel #
mapEval can process elements asynchronously but does it one-by-one.
In case we would like to run n tasks in parallel, we can use either mapParallelOrdered or mapParallelUnordered.
import scala.concurrent.duration._
val stream = {
Observable
.range(1, 5)
.mapParallelOrdered(parallelism = 2)(i =>
Task(println(s"$i: start asynchronously"))
.flatMap(_ => if (i % 2 == 0) Task.sleep(4.second) else Task.sleep(1.second))
.map(_ => i)
).foreachL(i => println(s"$i: done"))
}
// 2: start asynchronously
// 1: start asynchronously
// 1: done
// 3: start asynchronously
// 2: done
// 3: done
// 4: start asynchronously
// 4: done
The order of execution of Tasks inside mapParallelOrdered is nondeterministic, but they will always be passed to the downstream in the FIFO order, i.e. all done prints will have increasing indices in this example.
In case we don’t need this guarantee, we can use mapParallelUnordered which is faster. The code above would result in the following output:
2: start asynchronously
1: start asynchronously
1: done
3: start asynchronously
3: done
4: start asynchronously
2: done
4: done
flatMap (concatMap) #
Observable#flatMap (aliased to concatMap) applies a function which returns an Observable.
For each input element, the resulting Observable is processed before the next input element.
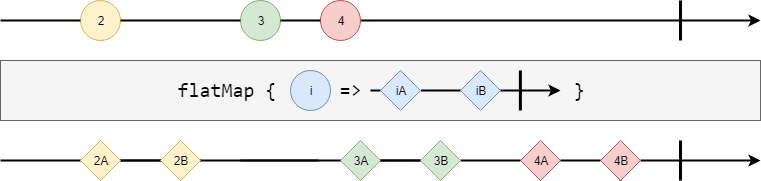
val stream = {
Observable(2, 3, 4)
.flatMap(i => Observable(s"${i}A", s"${i}B"))
.foreachL(println)
}
// 2A
// 2B
// 3A
// 3B
// 4A
// 4B
Note that if a function returns an infinite Observable, it will never process the next elements from the source:
val stream = {
Observable(2, 3, 4)
.flatMap(i => if (i == 2) Observable.never else Observable(s"${i}A", s"${i}B"))
.foreachL(println)
}
// Nothing is printed
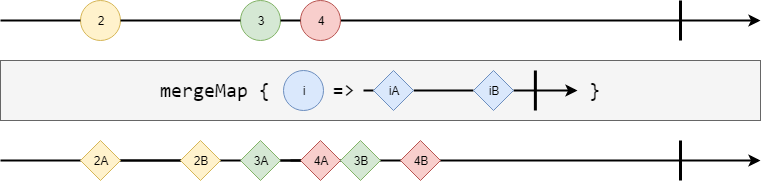
mergeMap #
Observable#mergeMap takes a function which can return an Observable but it can process the source concurrently. It doesn’t back-pressure on elements
from the source and subscribes to all of the Observables produced from the source until they terminate. These produced Observables are often called inner or child.
val source = Observable(2) ++ Observable(3, 4).delayExecution(50.millis)
val stream = {
source
.mergeMap(i => Observable(s"${i}A", s"${i}B").delayOnNext(50.millis))
.foreachL(println)
}
The possible result of the snippet above is depicted in the following picture:
Since the inner Observables are executed concurrently, we can also return an Observable which takes a very long time or does not terminate at all without slowing down the entire stream.
val stream = {
Observable(2, 3, 4)
.mergeMap(i => if (i == 2) Observable.never else Observable(s"${i}A", s"${i}B"))
.foreachL(println)
}
// 3A
// 3B
// 4A
// 4B
Keep in mind that mergeMap keeps all active subscriptions so it is possible to end up with a memory leak if we forget to close the infinite Observable.
In case one of the Observables returns an error, other active streams will be canceled and resulting Observable will return the original error:
val stream = {
Observable(2, 3, 4)
.mergeMap(i =>
if (i == 3) Observable.raiseError(DummyException("fail"))
else Observable(s"${i}A", s"${i}B").doOnSubscriptionCancel(Task(println(s"$i: cancelled")))
)
.foreachL(println)
}
// 2A
// 2B
// 4: cancelled
// Exception in thread "main" monix.execution.exceptions.DummyException: fail
switchMap #
Similar to mergeMap, Observable#switchMap does not back-pressure on elements from the source stream but instead switches to the first Observable returned by the provided function that will produce an element. It then cancels the other inner streams so there is only one active subscription at the time. It is safer than mergeMap in a way because there is no danger of a memory leak - although, it interrupts ongoing requests if something new arrives.
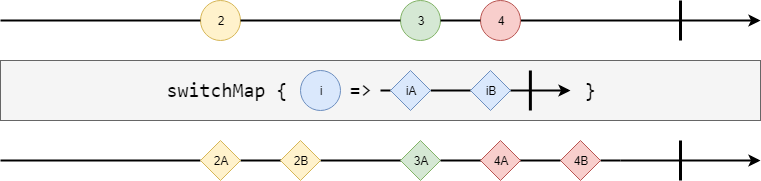
import cats.effect.ExitCase
def child(i: Int): Observable[String] = {
Observable(s"${i}A", s"${i}B", s"${i}C")
.delayOnNext(50.millis)
.guaranteeCase {
case ExitCase.Completed => Task(println(s"$i: Request has been completed."))
case ExitCase.Error(e) => Task(println(s"$i: Request has encountered an error."))
case ExitCase.Canceled => Task(println(s"$i: Request has been canceled."))
}
}
val stream = {
Observable(2, 3, 4)
.delayOnNext(100.millis)
.switchMap(child)
.foreachL(println)
}
// 2A
// 2: Request has been canceled.
// 3A
// 3B
// 3: Request has been canceled.
// 4A
// 4B
// 4C
// 4: Request has been completed.
Summary #
If you want to back-pressure a source Observable when emitting new events, use:
mapfor pure, synchronous functions which return only one valuemapEvalormapParallelfor effectful, possibly asynchronous functions which return up to one valueflatMapfor effectful, possibly asynchronous functions which return a stream of values
If you want to process source Observables concurrently, use:
mergeMapif you want to process all inner streamsswitchMapif you want to keep only the most recent inner stream
Scheduling #
Observable is a great fit not only for streaming data but also for control flow such as scheduling.
It provides several builders for this purpose and is quite easy to combine with Task if all you want is to
run a Task in specific intervals.
intervalWithFixedDelay (interval) #
Observable.intervalWithFixedDelay takes a delay and an optional initialDelay. It creates an Observable that
emits auto-incremented natural numbers (Longs) spaced by a given time interval. It starts from 0 with an initialDelay (or immediately),
after which it emits incremented numbers spaced by the delay of time. The given delay of time acts as a fixed
delay between successive events.
import monix.eval.Task
import monix.execution.schedulers.TestScheduler
import monix.reactive.Observable
import scala.concurrent.duration._
// using `TestScheduler` to manipulate time
implicit val sc = TestScheduler()
val stream: Task[Unit] = {
Observable
.intervalWithFixedDelay(2.second)
.mapEval(l => Task.sleep(2.second).map(_ => l))
.foreachL(println)
}
stream.runToFuture(sc)
sc.tick(2.second) // prints 0
sc.tick(4.second) // prints 1
sc.tick(4.second) // prints 2
sc.tick(4.second) // prints 3
intervalAtFixedRate #
Observable.intervalAtFixedRate is similar to Observable.intervalWithFixedDelay, but the time it takes to
process an onNext event gets deducted from the specified period. In other words, the created Observable
tries to emit events spaced by the given time interval, regardless of how long the processing of onNext takes.
The difference should be clearer after looking at the example below.
Notice how it makes up for time spent in each mapEval.
import monix.eval.Task
import monix.execution.schedulers.TestScheduler
import monix.reactive.Observable
import scala.concurrent.duration._
// using `TestScheduler` to manipulate time
implicit val sc = TestScheduler()
val stream: Task[Unit] = {
Observable
.intervalAtFixedRate(2.second)
.mapEval(l => Task.sleep(2.second).map(_ => l))
.foreachL(println)
}
stream.runToFuture(sc)
sc.tick(2.second) // prints 0
sc.tick(2.second) // prints 1
sc.tick(2.second) // prints 2
sc.tick(2.second) // prints 3
Error Handling #
Failing in any operator in an Observable will lead to the termination of the stream. It will inform the downstream and the upstream
about the failure, stopping the entire Observable chain - unless the error is handled.
Note that most errors should be handled at the Effect level (e.g. Task, IO in mapEval), and not by using Observable error handling operators.
If the Observable encounters an error, it cannot ignore and keep going. The best you can do (without using some bigger machinery) is to restart the Observable or replace it with different one.
handleError (onErrorHandle) #
Observable.handleError (alias for onErrorHandle) mirrors the original source unless an error happens - in which case it falls back to an Observable emitting one specific element generated by given total function.
import monix.reactive.Observable
val observable = Observable(1, 2, 3) ++ Observable.raiseError(new Exception) ++ Observable(0)
{
observable
.onErrorHandle(_ => 4)
.foreachL(println)
}
//=> 1
//=> 2
//=> 3
//=> 4
handleErrorWith (onErrorHandleWith) #
Observable.handleErrorWith (alias for onErrorHandleWith) mirrors the original source unless an error happens - in which case it falls back to an Observable generated by the given total function.
import monix.reactive.Observable
val observable = Observable(1, 2) ++ Observable.raiseError(new Exception) ++ Observable(0)
{
observable
.onErrorHandleWith(_ => Observable(3, 4))
.foreachL(println)
}
//=> 1
//=> 2
//=> 3
//=> 4
recover (onErrorRecover) #
Observable.recover (alias for onErrorRecover) mirrors the original source unless an error happens - in which case it falls back to an Observable emitting one specified element generated by given partial function. The difference between recover and handleError is that the latter takes a total function as a parameter.
recoverWith (onErrorRecoverWith) #
Observable.recoverWith (alias for onErrorRecoverWith) mirrors the original source unless an error happens - in which case it falls back to an Observable generated by the given partial function. The difference between recoverWith and handleErrorWith is that the latter takes a total function as a parameter.
onErrorFallbackTo #
Observable.onErrorFallbackTo mirrors the behavior of the source, unless it is terminated with an onError, in which case the streaming of events continues with the specified backup sequence regardless of the error.
import monix.reactive.Observable
val observable = Observable(1, 2) ++ Observable.raiseError(new Exception) ++ Observable(0)
{
observable
.onErrorFallbackTo(Observable(3, 4))
.foreachL(println)
}
//=> 1
//=> 2
//=> 3
//=> 4
This is equivalent to:
{
observable
.handleErrorWith(_ => Observable(3, 4))
}
onErrorRestart #
Observable.onErrorRestart mirrors the behavior of the source unless it is terminated with an onError, in which case it tries re-subscribing to the source with the hope that it will complete without an error.
The number of retries is limited by the specified maxRetries parameter.
There is also onErrorRestartUnlimited variant for an unlimited number of retries.
onErrorRestartIf #
Observable.onErrorRestartIf mirrors the behavior of the source unless it is terminated with an onError, in which case it invokes the provided function and tries re-subscribing to the source with the hope that it will complete without an error.
import monix.reactive.Observable
case object TimeoutException extends Exception
val observable = Observable(1, 2) ++ Observable.raiseError(TimeoutException) ++ Observable(0)
{
observable
.onErrorRestartIf {
case TimeoutException => true
case _ => false
}
.foreachL(println)
}
//=> 1
//=> 2
//=> 3
//=> 1
//=> 2
//=> 3
// ... fails and restarts infinitely
Retrying with delay #
Since Observable methods compose pretty nicely, you could easily combine them to write some custom retry mechanisms, like the one below:
def retryWithDelay[A](source: Observable[A], delay: FiniteDuration): Observable[A] =
source.onErrorHandleWith { _ =>
retryWithDelay(source, delay).delayExecution(delay)
}
It can be customized further. For example, we can also implement an exponential back-off:
def retryBackoff[A](source: Observable[A],
maxRetries: Int, firstDelay: FiniteDuration): Observable[A] = {
source.onErrorHandleWith {
case ex: Exception =>
if (maxRetries > 0)
retryBackoff(source, maxRetries-1, firstDelay*2)
.delayExecution(firstDelay)
else
Observable.raiseError(ex)
}
}
Dropping failed elements #
Sometimes we would like to ignore elements that caused failure and keep going, but
if something fails in an Observable operator (e.g. mapEval), the entire Observable is stopped with a failure.
val observable = Observable(1, 2, 3)
def task(i: Int): Task[Int] = {
if (i == 2) Task.raiseError(DummyException("error"))
else Task(i)
}
{
observable
.mapEval(task)
.foreachL(e => println(s"elem: $e"))
}
//=> elem: 1
//=> Exception in thread "main" monix.execution.exceptions.DummyException: error
There is nothing like a supervision mechanism (like in Akka Streams), but if we control it at the Effect level, we could achieve similar behavior.
For instance, we could wrap our elements in Option or Either and then do a collect { case Right(e) => e }.
val observable = Observable(1, 2, 3)
def task(i: Int): Task[Int] = {
if (i == 2) Task.raiseError(DummyException("error"))
else Task(i)
}
{
observable
.mapEval(task(_).attempt) // attempt transforms Task[A] into Task[Either[Throwable, A]] with all errors handled
.collect { case Right(evt) => evt}
.foreachL(e => println(s"elem: $e"))
}
//=> elem: 1
//=> elem: 3
It’s not as nice as having one global Supervisor that handles the errors if something goes wrong, but as long as you follow
basic rules such as not throwing exceptions and remembering that any Task can fail then you should be good to go.
MonadError instance #
The Observable provides a MonadError[Observable, Throwable] instance so you can use any MonadError operator for error handling.
If you are curious what it brings you in practice, check the methods in cats.MonadError and cats.ApplicativeError.
Many of these methods (and more) are defined directly on the Observable and the rest can be acquired by calling import cats.implicits._.
Reacting to internal events #
If you remember, an Observable internally calls onNext on every element, onError during error and onComplete after
stream completion. There are many other methods for executing a given callback when the stream acquires a specific type of event.
Usually these method names start with doOn or doAfter.
doOnNext #
Executes a given callback for each element generated by the source Observable, useful for doing side-effects.
var counter = 0
val observable = Observable(1, 2, 3)
{
observable
.doOnNext(e => Task(counter += e))
.foreachL(e => println(s"elem: $e, counter: $counter"))
}
//=> elem: 1, counter: 1
//=> elem: 2, counter: 3
//=> elem: 3, counter: 6
You could also write it preserving referential transparency using Ref from Cats-Effect:
import cats.effect.concurrent.Ref
import monix.eval.Task
import monix.reactive.Observable
def observable(counterRef: Ref[Task, Int]): Task[Unit] = {
Observable(1, 2, 3)
.doOnNext(e => counterRef.update(_ + e))
.mapEval(e => counterRef.get.map(counter => println(s"elem: $e, counter: $counter")))
.completedL
}
Ref[Task].of(0).flatMap(observable)
// After executing:
//=> elem: 1, counter: 1
//=> elem: 2, counter: 3
//=> elem: 3, counter: 6
There is also a doOnNextF variant which works for data types other than Task.
Subjects #
Subject acts both as an Observer and as an Observable. Use Subject if you need to send elements to the Observable
from other parts of the application.
It is presented in the following example:
import monix.eval.Task
import monix.execution.Ack
import monix.reactive.subjects.ConcurrentSubject
import monix.reactive.{MulticastStrategy, Observable, Observer}
val subject: ConcurrentSubject[Int, Int] =
ConcurrentSubject[Int](MulticastStrategy.replay)
def feedItem[A](observer: Observer[A], item: A): Task[Ack] = {
Task.deferFuture(observer.onNext(item))
}
def processStream[A](observable: Observable[A]): Task[Unit] = {
observable
.mapParallelUnordered(3)(i => Task(println(i)))
.completedL
}
{
Task
.parZip2(
feedItem(subject, 2),
processStream(subject)
)
}
Subject is also often used to specify a multicast strategy in shared (hot) Observables to specify which elements are sent to
new subscribers. There are several strategies available - you can find their short characteristics below.
AsyncSubjectemits the last element (and only the last value) emitted by the source and only after the source completes.BehaviorSubjectemits the most recently emitted element by the source, or theinitialValuein case no element has yet been emitted, then continue to emit events subsequent to the time of invocation.ConcurrentSubjectallows feeding events without the need to respect the back-pressure (waiting onAckafteronNext). It is similar to an Actor and can serve as its replacement in many cases.PublishSubjectemits to a subscriber only those elements that were emitted by the source subsequent to the time of the subscription.PublishToOneSubjectis aPublishSubjectthat can be subscribed at most once.ReplaySubjectemits to a subscriber all the elements that were emitted by the source, regardless of when the observer subscribes.Varemits the most recently emitted element by the source, or theinitialelement in case none has yet been emitted, then continue to emit events subsequent to the time of invocation via an underlyingConcurrentSubject. This is equivalent to aConcurrentSubject.behavior(Unbounded)with the ability to expose the current value for immediate usage on top of that.
For more information, refer to descriptions and methods in monix.reactive.subjects package.
Sharing an Observable #
As mentioned before - an Observable doesn’t emit any items until something subscribes to it.
If it can serve only one subscriber it is called a cold Observable.
On the other hand there is also a notion of a hot Observable denoted as a ConnectableObservable whose source can be shared between many subscribers.
ConnectableObservable #
Similar to the standard version, a ConnectableObservable is lazy, i.e. it will start processing elements after
processing connect(). The crucial difference is that mapping a ConnectableObservable returns an Observable which
shares the source according to the specified strategy, represented by a Subject.
Consider the following example which uses publish to create a ConnectableObservable on top of a PublishSubject:
import monix.eval.Task
import monix.execution.{Cancelable, Scheduler}
import monix.reactive.Observable
import monix.reactive.observables.ConnectableObservable
import scala.concurrent.duration._
implicit val s = Scheduler.global
val source: ConnectableObservable[Long] = {
Observable.intervalAtFixedRate(100.millis)
.doOnNext(i => Task(println(s"source: $i")))
.publish
}
// at this point source starts printing
val cancelable: Cancelable = source.connect()
val o1: Task[Unit] = source.take(2).foreachL(i => println(s"o1: $i")).delayExecution(200.millis)
val o2: Task[Unit] = source.take(1).foreachL(i => println(s"o2: $i"))
Task.parZip2(o1, o2).map(_ => cancelable.cancel())
// Sample Output after running:
// source: 0
// source: 1
// source: 2
// o2: 2
// source: 3
// o1: 3
// source: 4
// o1: 4
Calling connect() starts the streaming. In this case, it has managed to process 3 elements before o2 subscribed,
so it didn’t receive all of them. It only received one element because of take(1). If it was a normal Observable it would have been
canceled - but that’s not the case with ConnectableObservables. Whenever each subscriber stops, it just unsubscribes.
If it weren’t for cancelable.cancel() it would have keep to going on even after all the subscribers stopped listening. Also, note the
source was ran only once.
Back-pressure #
A source ConnectableObservable is back-pressured on all subscribers. In other words, it will wait for an acknowledgement from
all active subscribers before processing the next element.
Let’s see it on an example:
import monix.eval.Task
import monix.execution.{Cancelable, Scheduler}
import monix.reactive.Observable
import monix.reactive.observables.ConnectableObservable
import scala.concurrent.duration._
implicit val s = Scheduler.global
val source: ConnectableObservable[Int] = {
Observable(1, 2, 3)
.delayExecution(1.second) // delay to ensure subscribers will get all elements
.doOnNext(i => Task(println(s"source: $i")))
.publish
}
val cancelable: Cancelable = source.connect()
val o1: Task[Unit] = source.delayOnNext(2.second).foreachL(i => println(s"o1: $i"))
val o2: Task[Unit] = source.foreachL(i => println(s"o2: $i"))
Task.parZip2(o1, o2)
// Sample Output after running:
// source: 1
// o2: 1
// -- 2 second delay --
// o1: 1
// source: 2
// o2: 2
// -- 2 second delay --
// o1: 2
// source: 3
// o2: 3
// -- 2 second delay --
// o1: 3
It might not be always desirable if we don’t want to slow down the producer. There are several ways to handle it, depending on the use case. In general, if we don’t want back-pressure, we need a buffer with a proper overflow strategy.
For instance, we could introduce a buffer per subscriber which can store up to 10 elements and then starts dropping new elements:
val subObservable = source.whileBusyBuffer(OverflowStrategy.DropNew(10))
We could even disable back-pressure completely with a function like whileBusyDropEvents.
From the perspective of the source, the subscriber is always processing elements right away so it doesn’t have to wait on it.
Configuring underlying Subject #
For all plain Subjects, there are corresponding methods, i.e. publish, publishLast, replay etc.
Different Subjects vary in behavior with regard to subscribers, but source Observables will always be executed just once.
For instance, a ReplaySubject will cache and send all elements to new subscribers:
implicit val s = Scheduler.global
val source: ConnectableObservable[Int] = {
Observable(1, 2, 3)
.doOnNext(i => Task(println(s"source: $i")))
.replay
}
val cancelable: Cancelable = source.connect()
val o1: Task[Unit] = source.foreachL(i => println(s"o1: $i"))
// Sample Output after running:
// source: 1
// source: 2
// source: 3
// o1: 1
// o1: 2
// o1: 3
Another example could be BehaviorSubject which remembers the latest element to feed to new subscribers:
implicit val s = Scheduler.global
val source: ConnectableObservable[Int] = {
Observable(1, 2, 3)
.doOnNext(i => Task(println(s"source: $i")))
.behavior(0)
}
val cancelable: Cancelable = source.connect()
val o1: Task[Unit] = source.foreachL(i => println(s"o1: $i"))
// Sample Output after running:
// source: 1
// source: 2
// source: 3
// o1: 3
If it were a PublishSubject, the subscriber would not receive any elements because the source has processed everything
before subscription.
Doing it the pure way #
As you probably noticed, ConnectableObservable is not very pure because the time of subscription can completely change the result
and the original source is processed only once. Monix also exposes publishSelector and pipeThroughSelector which allows
you to take advantage of Hot Observables in more controlled and purely functional fashion.
implicit val s = Scheduler.global
val source = {
Observable(1, 2, 3)
.doOnNext(i => Task(println(s"Produced $i"))
.delayExecution(1.second))
}
def consume(name: String, obs: Observable[Int]): Observable[Unit] =
obs.mapEval(i => Task(println(s"$name: got $i")))
val shared = {
source.publishSelector { hot =>
Observable(
consume("Consumer 1", hot),
consume("Consumer 2", hot).delayExecution(2.second)
).merge
}
}
shared.subscribe()
The code would print the following output twice:
Produced 1
Consumer 1: got 1
Produced 2
Consumer 1: got 2
Consumer 2: got 2
Produced 3
Consumer 1: got 3
Consumer 2: got 3
A source Observable is shared only in the scope of publishSelector and we can freely reuse its result and the original source.
publishSelector uses PublishSubject. It is possible to customize it with a pipeThroughSelector:
final def pipeThroughSelector[S >: A, B, R](pipe: Pipe[S, B], f: Observable[B] => Observable[R]): Observable[R]
Pipe has variants for all types of subjects, e.g. source.pipeThroughSelector(Pipe.replay[Int], f).
Interoperability with other Streams API (Akka Streams, FS2) #
Due to compatibility with the Reactive Streams
specification, an Observable allows good interoperability with other libraries.
The next subsections contain examples how to convert between Monix Observable and
two other popular streaming libraries, but it should work in similar way with every other library
compatible with Reactive Streams protocol.
Akka Streams #
Necessary imports and initialization for Akka Streams:
import monix.reactive.Observable
import monix.execution.Scheduler.Implicits.global
import akka._
import akka.stream._
import akka.stream.scaladsl._
import akka.actor.ActorSystem
implicit val system = ActorSystem("akka-streams")
implicit val materializer = ActorMaterializer()
To convert an Akka Source to a Monix Observable:
val source = Source(1 to 3)
// source: akka.stream.scaladsl.Source[Int,akka.NotUsed] = Source(SourceShape(StatefulMapConcat.out(1887925338)))
val publisher = source.runWith(Sink.asPublisher[Int](fanout = false))
// publisher: org.reactivestreams.Publisher[Int] = VirtualPublisher(state = Publisher[StatefulMapConcat.out(1887925338)])
val observable = Observable.fromReactivePublisher(publisher)
// observable: monix.reactive.Observable[Int] = monix.reactive.internal.builders.ReactiveObservable@72f8ecd
To go back from a Monix Observable to an Akka Source:
val observable = Observable(1, 2, 3)
// observable: monix.reactive.Observable[Int] = monix.reactive.internal.builders.IterableAsObservable@4783cc8
val source = Source.fromPublisher(observable.toReactivePublisher)
// source: akka.stream.scaladsl.Source[Int,akka.NotUsed] = Source(SourceShape(PublisherSource.out(989856637)))
FS2 #
To go between an FS2 Stream
and a Monix Observable you need to use the fs2-reactive-streams
library, but otherwise the conversion remains very straightforward.
Necessary imports:
import cats.effect._, fs2._
import fs2.interop.reactivestreams._
import monix.reactive.Observable
import monix.execution.Scheduler.Implicits.global
To convert an FS2 Stream to a Monix Observable:
val stream = Stream(1, 2, 3).covary[IO]
// stream: fs2.Stream[cats.effect.IO,Int] = Stream(..)
val publisher = stream.toUnicastPublisher()
// publisher: fs2.interop.reactivestreams.StreamUnicastPublisher[cats.effect.IO,Int] = fs2.interop.reactivestreams.StreamUnicastPublisher@6418f777
val observable = Observable.fromReactivePublisher(publisher)
// observable: monix.reactive.Observable[Int] = monix.reactive.internal.builders.ReactiveObservable@7130d725
To go back from a Monix Observable to an FS2 Stream:
val observable = Observable(1, 2, 3)
// observable: monix.reactive.Observable[Int] = monix.reactive.internal.builders.IterableAsObservable@4783cc8
val stream = observable.toReactivePublisher.toStream[IO]
// stream: fs2.Stream[cats.effect.IO,Int] = Stream(..)